
A Panel Conversation on A/B Testing Statistics with Chris Stucchio, John Meakin, and Georgi Georgiev
If you’re like me, you have enough statistics knowledge to get by but, from time to time, you need to ask an expert to make sure that your Experiments are drive decisions based on statistically valid data. I had the opportunity to ask the folks whom I consider leaders in Experimentation statistics some of the questions I’m sure you’ve had at one time or another. We covered a wide range of topics such as whether you should be running tests during the current pandemic, things should you avoid when estimating the impact of an Experiment, and some of the key differences between Bayesian and Frequentist. Enjoy!
Hi everyone, thank you all for taking the time to chat with us today! Since you all are statistics leaders in the Experimentation space, I wanted to pick your brains about some of the big questions on Experimenter’s minds these days. But before we dive in, let’s do a quick round table. If you folks could kindly introduce yourselves and what you do, we can go from there. I’ll start.
Hi everyone. I’m Rommil Santiago, I’m the Experimentation lead for my company—?and I’ll be leading the panel today.
Chris:
I’m Chris Stucchio, a long time blogger on statistics and experimentation and the designer of VWO’s SmartStats. More generally I’m a data scientist and engineer focused on building intelligent computer programs that replace human decision making.
Georgi:
I’m Georgi Georgiev, the author of ‘Statistical Method in Online A/B Testing’. I operate an internet marketing/web analytics consultancy agency called Web Focus which is also behind products like Analytics-Toolkit.com. You can find a lot of my writings on A/B testing stats on Analytics Toolkit’s blog.
John:
I’m John Meakin, I’m the lead statistician and head of experimentation at Vrbo (Vrbo is an online marketplace for vacation rentals that makes it easy and fun to book cabins, condos, beach houses and every kind of space in between)?—?I set the guidelines for experimental methodologies at Vrbo and recently have become more involved with this at Expedia Group as well. Part of my work involves researching and developing methodologies to advance the experimentation platform’s capabilities and tools across Expedia Group. I also consult with product and engineering teams running experiments.
Welcome, everyone.
Needless to say, COVID-19 is a terrible thing and I hope you all are staying well and healthy. What are your thoughts on running Experiments these days and what are the top things we should consider from a statistics perspective should we decide to do so?
Chris:
Let me start by discussing modelling assumptions?—?a key factor underlying the validity of any experiment. Consider an experiment designed to make a long term change to our product?—?the modelling assumption being made is that customer behaviour during the experimental period will be very similar to customer behaviour in the long term.
As an example of this modelling assumption being false, consider an experiment run from Feb 7-Feb 14 at a flower shop. A variation talking about Valentine’s day will certainly beat a variation talking about funerals, banquet centrepieces and religious ceremonies that week. But it will underperform the rest of the year.
If we apply this idea to experiments run right now, we can see that many experimental results are likely invalid once the crisis is over and we return to normal. “Toilet paper?—?in stock!” is a winner today but (hopefully!) boring and unremarkable in 2021.

What this means statistically is we should prefer faster experiments that provide lower confidence. To begin with, you need to form an opinion about how long you think COVID-19 will last?—?how to do that is beyond the scope. Then you can change the confidence in your tests based on what you think will happen. For example:
- If you think the crisis has 1 more month, a 3-week experiment only gives you 1 week to actually profit from the winner. Run a 1-week experiment and pick whatever wins, accepting that fast decisions are not necessarily the best.
- In contrast, if you expect 6 more months, a 3-week test to get good confidence is perfectly reasonable.
(As a tangential note on predicting the crisis, consider the following analogy. A man has just lost all his money playing poker or roulette. He then turns to the crowd and says “I have a Ph.D., stop listening to the guy who took all my chips!” In this crisis, techbro data geeks like Balaji Srinavasan won all the chips with correct predictions. The WHO/CDC/etc?—?for all their degrees?—?have been grossly wrong on essentially everything. I know who I’m listening to.)
“What this means statistically is we should prefer faster experiments that provide lower confidence.”
Georgi:
From a statistics perspective?—?not much to say here. A good statistical analysis for your typical A/B test remains the same, virus pandemic or not. However, there are certain precautions that need to be taken with regards to external validity that is?—?how well results from the test will generalize going forward.
As I’ve explained in my seminal piece on the generalizability of A/B tests, the representativeness of a test sample depends on three things: time-dependent factors, population difference (or change) factors, and the presence or absence of learning effects in both directions. Since the extreme measures taken in many locales result in altered user behaviour, tests in industries which are significantly affected by that will carry a higher risk for their results not generalizing well to a post-pandemic situation.
That doesn’t mean one should not be running tests, even in highly affected industries. What you need to do, however, is review each test from the point of the hypothesized mechanism through which the intervention is supposed to work. You should consider if it is dependent on fairly immutable characteristics of human beings or if it is more subject to distortions from prevailing attitudes in the moment. On the one hand, if what you are testing is supposed to work by exploiting cognitive processes and time-tested design principles, then the risk of the test results not generalizing well is much smaller. The same goes for tests which serve the purpose of post-release QA.
On the other hand, if you experiment with things that might depend on the presence of certain spending habits or proclivities, then those would be more suspect. I’d be setting these aside for potential retesting once the atypical situation is over. I would not discourage testing such ideas either since A.) they might work splendidly during the crisis and given that it can easily last for a year or more, why not reap the benefits during that time, and B.) the effect might persist afterwards, but to a smaller (or larger) degree. Note that you want to retest even inconclusive tests of this nature as what hadn’t worked during the pandemic might work afterwards!
“You should consider if it is dependent on fairly immutable characteristics of human beings or if it is more subject to distortions from prevailing attitudes in the moment.”
John:
Whether we’re in a global pandemic or not, some of the most critical things to think about when running experiments is the extent to which they are internally and externally valid.
For context, an internally valid experiment allows for definitive causal interpretation and issues with internal validity in online experiments usually arise because of flaws in the design (e.g. whether users are randomized properly, whether enough data is collected, and whether the correct statistical models are used). For example, if the person designing the experiment intends for 50% of visitors to see each variant, but the data shows a split of 49%/51% then it’s highly likely the results do not actually carry meaning about the true underlying impact.
External validity on the other hand refers to the extent to which the results of an experiment will generalize to other settings (e.g. different times of year or for a different cohort of visitors). For example, an experiment testing whether it’s a good idea to highlight a property’s distance to the beach may be a big winner when visitors are shopping for summer vacations but may be neutral when people are shopping for winter vacations.

From the examples above, you can see that these issues are present even in normal times, but right now they are likely causing much more of a problem. From an internal validity perspective, the issue is pretty clear; many sites will have less traffic and fewer purchasers than is typical?—?so experiments will need to run for longer to achieve the same degree of certainty. However, much more concerning, but unfortunately also much less easy to quantify is the external validity problem. Visitors shopping on any site right now may fundamentally behave differently (or be composed of a much different mix all together) than is typical. Experimenters should be very cautious of the types of experiments run now, should think much harder about whether they’ll believe the results are externally valid and should question more stringently the learnings derived from them.
“Experimenters should be very cautious of the types of experiments run now, should think much harder about whether they’ll believe the results are externally valid…”
Moving on. No matter what’s going on in the world, senior leadership will always ask what impact an Experiment result will have on annual revenue.
How do you suggest Experimenters respond to such requests, and if push comes to shove, how would you approach forecasts and projections based on Experimental outcomes?
Georgi:
I’d include caveats in all prognoses made from tests during this period?—?some more severe than others, depending on the type of hypothesis being tested. The caveat will basically be that results obtained from this test might not generalize well so any long-term prognosis is provisional. It’s not what anyone wants, but the alternative is to simply pretend we can ignore the extraordinary circumstances.
John:
These requests are very challenging because often a lot of investment is put into experimentation (both from a platform and product perspective) and leaders want to be able to demonstrate their investments are paying off, and an experiment is one of the best ways to do that.
Unfortunately, in many cases, experiments are not run with the goal of providing annualized forecast and that is a good thing. To move quickly and to enable rapid iteration and product development, many experiments simply need to provide enough evidence for a binary decision (in very simple terms, this means we’re often only testing whether the difference between thing A and thing B is conclusively “not zero”)…So while the result from that test might be “significant” the actual magnitude of the impact can still be quite uncertain?—?and again, in most cases, that is okay! We know it’s unlikely to be zero (and even more unlikely to be negative) so we can move on to the next idea.
If we wanted for each experiment to provide conclusive estimates of annual financial impact we’d need to test in a completely different way. For example, not only would tests need to run longer, but we’d need to be able to model other factors (e.g. seasonality, test interaction, etc.?—?quite related to the issues with external validity raised above). Alternatively, we could invest in holdout groups, but this has some quite interesting complexities and costs (e.g. it reduces traffic from live testing, it may require maintaining two codebases, and making decisions about whether and which incidents to address in each).
So, I believe fundamentally this comes down to two things 1) good communication about the true uncertainty of any forecast, and 2) identifying other ways to quantify the impacts of experiments that still provides leaders with meaningful ways to compare the relative magnitude of wins and losses and also to make tradeoff decisions.
“If we wanted for each experiment to provide conclusive estimates of annual financial impact we’d need to test in a completely different way.”
Chris:
I would include a range of projections that make the uncertainty and modelling assumptions very clear. An example of 1-year projections for an experiment generating an extra $20k/week:
https://sheetsu.com/tables/621260c018
I would additionally emphasize the uncertainty involved in these estimates, and how they might change depending on the crisis.
As a follow-up to that. What are some of the things Experimenters should absolutely avoid doing when creating forecasts and projections?
John:
Per the above, I think experimenters should avoid forecasting unless they have the proper data to validate all the assumptions (which they often don’t). But, if push comes to shove, they should avoid providing forecasts that are not properly caveated with how inherently uncertain they are.
“…avoid providing forecasts that are not properly caveated with how inherently uncertain they are.”
Chris:
P-hacking, or playing with the numbers until they give the desired result. This is always tempting?—?I’ve certainly felt it?—?but must be resisted at all costs.

Georgi:
Overstating their claim or understating its uncertainty, two sides of the same coin, usually. You want to be upfront about the key inherent assumptions and ideally explore different possible scenarios based on ranges within which these might be violated.
So obviously, it’s very easy for inexperienced Experimenters and even some experienced ones to make mistakes when it comes to Experimentation.
“You want to be upfront about the key inherent assumptions…”
Changing hears once more. Statistics, clearly, can be very nuanced and it’s easy to make mistakes?—?even well-intentioned once. Let’s talk about how organizations should structure themselves.
Should statisticians be embedded into every team? Should we be training Experimenters on statistics? Or should there be a central team analyzing all results? What’s your take?
Chris:
My general view is you should have a centralized experimentation group that builds automation/processes that other teams use. This group should be independent of most other teams; their job is going to be a lot of “cool idea but it didn’t work” reports and many people will attempt to subvert this. P-hacking?—?torturing the numbers until they say what you want (“hey boss, my idea worked!”)?—?is a very real phenomenon.
Separately, the executives at the company need to give this group deference when the group sticks to evaluating projects and experiments.
Ultimately the goal should be to make experimentation as standardized and easy as possible. Most experiments should follow a small number of templates (“test a thing at the top of the funnel, success metric = opportunities / MQLs”), which are entirely automated.
I also don’t think “experimenter” should be a job title?—?rather, it’s just housekeeping that everyone does when they want to change things. The job of the experimentation group is minimizing the work needed for others to do clean experiments.
“My general view is you should have a centralized experimentation group that builds automation/processes that other teams use.”
Oh? What would you call them then?
Chris:
The job of identifying/fixing bottlenecks in the checkout process is design or UX. The job of running an email campaign is marketing. Coming up with the ideas/execution isn’t a new or special “experimentation” job. It’s the same old UX/design/marketing job?—?all that’s new is is that we’ve replaced “does the boss like it” with “do customers like it”.
After the designer or marketer does their job, they roll it out to a test group as per the standards of the experimentation group. Tools built by the experiment group then determine if it’s a winner or loser.
The experimentation group will have job titles like “statistician”, “data scientist” or “engineer”. They are rarely involved in the day to day and mostly just build tools/processes.
In all of this, there’s no “experimenter” job title or role. All there is is one extra step in the release process, namely the step of checking with customers whether what was built actually had an effect.
Georgi:
Interesting. I always thought the job of an experimenter is to help design, execute and analyze experiments so they answer the questions posed in an efficient (business-wise) and rigorous way. A task which many UX, marketing, etc. people will easily botch as we see all around us. Software is not an adequate replacement, though a well-designed one may help avoid some mistakes.
I feel this is similar to the differentiation between terms CRO and Experimentation. My point of view is very much like that of Georgi’s where Experimentation is an enablement team. At least that’s how I see it where I work today.
Georgi:
The answer to this question might be different for different organizations and I think most are already A/B testing how to organize their experimentation programs, if that makes sense.
Given the fact that the design and analysis of experiments is perhaps the most difficult discipline there is, I don’t think it is reasonable to expect that high-quality business experiments can happen with a distributed system of design and analysis. We have learned a lot on that front over the last 120 years. For example, medical statistics was in a pretty poor state for many decades precisely because the people designing the experiments and analyzing the results were MDs, not professional researchers and statisticians. It was like expecting from most statisticians to become good heart surgeons with a few weeks of training. The field is without question in a much better state nowadays as professional scientists have been called upon.

On the opposite end is agricultural science wherein experiments were never done by farmers, it was always professional researchers who set them up. It is, therefore, no coincidence that a lot of early breakthroughs in statistics came from that field (and continue to this day!). The same goes for successes in military experiments where during WWII armies were hiring the top statisticians of their day and that resulted in a number of high-quality works and breakthroughs.
The above, however, is not stopping many companies from attempting to turn all of their developers, and front-end designers into capable experimenters. Yes, the tools they have at their disposal are much better than anything we’ve had before, but I don’t think the tooling was ever the major issue in similar attempts. It is the overarching philosophy, the understanding of risk and reward, probabilistic thinking, etc. It remains to be seen if democratizing experimentation is the way to go or whether centralized business research and risk management teams would prove to be a must.
“I don’t think it is reasonable to expect that high-quality business experiments can happen with a distributed system of design and analysis.”
John:
The answer to this question obviously depends a lot on the size and of the organization and the experimentation culture; so I will answer with an eye towards larger organizations that have already adopted an experimentation culture and are looking to optimize it.
It is fundamental to have a solid core experimentation team (engineers, statisticians, as well as a management structure around this) dedicated solely to improving and maintaining the end to end the experimentation process. This team needs to work closely to build tools and processes designed for proper experimentation. To be clear, this does not mean that this team actually runs experiments, ideates them, or even implements them in the code. It is simply is a core team dedicated to enabling the end to end process.
It would be challenging to have a statistician for every team, the organization described above needs to enable people trained in statistical modelling and experimental design to be involved as consultants for the different product teams actually running tests.
“…people trained in statistical modelling and experimental design [need] to be involved as consultants for the different product teams actually running tests.”
You all touched on issues with deep analysis. What role does Automation play in helping Experimenters avoid errors in analysis and do you ever see Automation replacing statisticians?
Chris:
I’m a huge proponent of automation. If you want more of something, the best way to make that happen is to make it cheaper. If a web designer can set up an experiment in one click and don’t need to ask the statistician for help, they’ll A/B test more things. Also, in my experience doing many tests manually, most A/B tests are exactly the same from the statistical perspective. You don’t lose much by removing the analyst.
The main value I see in keeping statisticians in the game is designing the automation to account for things specific to your business.
As an example, consider my previous job at a subprime moneylender. In that role it would have been pointless for us to A/B test the conversion rate, defined as (# of people who borrow) / (# of people who see a loan offer). If we get 100 extra borrowers but 20 of them go delinquent, that’s actively harmful to the business. Getting 100 extra borrowers who repay and churn (never borrow again) was harmless but a net-zero in terms of the bottom line.
My job as the statistician was to find (and build automation to repeatably measure) a single metric that properly accounts for business value?—?in our case, a metric accounting for conversion rate, delinquency and customer retention.

Georgi:
Automation is great as long as it operates in a sound framework and results in increased productivity. Over the past several decades we’ve experienced automation of processes which previously occupied the majority of a statistician’s time. Yet, demand for statistical expertise is higher than it ever was as evidenced by the volume of job positions and corresponding salary levels. I have some understanding of basic economics so I don’t see any kind of automation replacing statisticians any day soon, except in very specific domains (and even there I’m doubtful).
“Automation is great as long as it operates in a sound framework and results in increased productivity.”
John:
This is quite related to what Chris and Georgi have said?—?Having an end-to-end experimentation process that is as automated as possible is fundamental to realizing the true value of experimentation. Your question just touches the surface of what a fully functioning platform needs. For example, automating the process for experimentation design or automatically identifying problems with experiments early (e.g. flagging tests that will not be internally valid) is critical to long term success. However, I don’t believe this kind of automation will ever replace statisticians. In fact, the way this automation is developed needs to be at least informed, and perhaps even designed by a statistician.
Here’s a curve-ball. Offline experimentation. At a high-level, because sample sizes can be small, how would you suggest Experimenters approach offline experimentation? Is it possible to even use statistics in these settings?
Chris:
I’d suggest having statisticians be involved with offline experimentation from the start. This sort of contradicts what I said before about automation, so let me explain why I think differently here.
In an online A/B test run in VWO or Optimizely, everything is quite standardized. You have two landing pages, randomization across pages is very good, and new visitors are fairly cheap. This makes experiments cheap and reliable; in contrast, a statistician is expensive and there aren’t too many errors you can fix by having one involved.
In contrast, offline tests are often very expensive. They also have more moving parts?—?e.g., you may need to train half your ops team with a new script or alter the branding of half your stores. Any of these can introduce statistical issues which the statistician can spot. The cost of a statistician is still high, but it’s low relative to the cost of the errors they are possibly preventing.
I feel this. Particularly in larger organizations?—?there are a lot of factors to offline experimentation that many don’t appreciate. Go on.
Chris:
I’ll also emphasize that you need statisticians with a certain kind of practical mindset here?—?many are unsuited to this role.
I’ll relay an anecdote (with some details altered to protect the guilty). I once had a smart statistician suggest using Natural Language Processing to predict which language a prospect might prefer. This is a plausible project; Tendulkar and Toraskar probably speak Marathi. But a wiser man instead used a lookup table based on their state (Maharashtra -> Marathi, Telangana -> Telugu), implemented with a simple rule in Salesforce.
For offline experimentation a certain degree of wisdom is needed.
Once again, I really feel what you are saying. A big part of what I do is to push product managers to truly take an MVP approach.
“…offline tests are often very expensive. They also have more moving parts?—?e.g., you may need to train half your ops team with a new script or alter the branding of half your stores.”
Georgi:
Why would sample sizes be small? It all depends on what you’re trying to affect and therefore measure. As far as I’m aware there is a great deal of offline business experimentation going on, and with significant success, too.
That’s a fair point, as always. John?
John:
Statistics and experimentation have been married since the early 1900s?—?long before any applications in online settings. Funny you should question whether statistics is possible in these settings though because when sample sizes are small, the statistical models you use are way more important than in most large-scale online settings (where the central limit theorem often dominates). Before getting into online experimentation I spent almost 6 years in “offline” experimentation in education where sample sizes were as low as 50–70 schools?—?There were still conclusive “winners.”
“…when sample sizes are small, the statistical models you use are way more important than in most large-scale online settings…”
Love it.
I typically ask Experimenters if they are pro-Frequentist or Pro-Bayesian. But as a change of pace, since both approaches can be used in Experimentation, how about you share with our readers one benefit of Frequentist and one benefit of Bayesian?
John:
The frequentist approach benefits from being extraordinarily transparent about how the uncertainty of results are generated (i.e. fairly simple formulas and few assumptions can generate p-values and confidence intervals). It is also simple to implement and maintain at scale. To its detriment, the results are often misinterpreted or hard to understand for most (e.g. “the result of this test is a 3% lift +/- 5% with 95% confidence so we fail to reject the hypothesis that the variants are equal”)?—?So it takes dedicated work to make sure misinterpretation doesn’t happen.
I think “dedicated” is putting it very mildly. Sometimes, I feel it’s like herding cats. Haha. And what about Bayesian?
John:
The Bayesian approach benefits from much more understandable statements about the uncertainty of results (i.e. “the probability of this test being negative is 10%, the probability of this test being neutral is 90%…”). However, in order to understand whether those statements are accurate (and the degree to which their accuracy varies based on underlying assumptions) can be extraordinarily complex even for the people designing the models that generate them?—?So it takes dedicated work to justify those assumptions and maintain their accuracy.
Georgi:
Frequentist methods produce the essential thing for any decision-making process you might want to apply to a given business decision, namely objective error rates with finite-sample guarantees. I’m happy to credit Bayesian methods for their use in Experimentation as soon as one can show me how to untangle so-called Bayesian inference from Bayesian decision-making.
“I’m happy to credit Bayesian methods for their use in Experimentation as soon as one can show me how to untangle so-called Bayesian inference from Bayesian decision-making.”
Chris:
I disagree with Georgi here?—?this is completely built into the Bayesian way of thinking.
Bayesian inference is about computing a posterior. The posterior distribution is your inference?—?your belief about the state of the world. That’s it, there’s no decision involved here.
Bayesian decision-making, in contrast, is about minimizing our monetary losses. Not all mistakes are equal?—?losing $1 is much less bad than losing $100. This is the “loss function”.
Obviously this could go back and forth for a while. Y’know, I think a Bayesian vs. Frequentist debate would be interesting for a future conversation. Clearly there is a lot of passion here.
Sorry to interrupt, Chris. Go on. One pro-Bayesian and one-Frequentist point.
So first of all, I want to say that I think this distinction is overplayed, particularly for measuring conversion rates where Beta-Binomial distributions rapidly approach the normal distribution.
First of all, let me define my terms. Frequentist methods are methods where the focus is on test accuracy (i.e. false positive and false negative probabilities) for a fixed value of a hidden variable (e.g., the true conversion rate). Bayesian methods go a step further and assign probabilities to different values of the hidden variable.
Bayesian methods are great when the world is indifferent to you and you know a bit about it. As an example, consider an experiment designed to increase revenue/visitor at an eCommerce site. Here’s a fact about eCommerce: if we make a histogram of revenues generated by different visitors, it has a well-understood shape?—?a spike and slab:
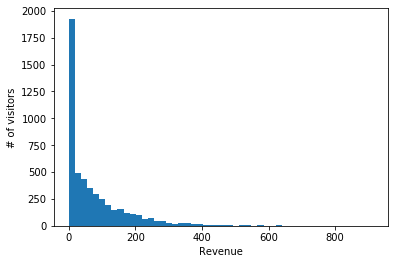
The “spike” at $0 means that a certain fraction of visitors never checkout and generate zero revenue. The “slab” means that the remaining 100-X% of customers do check out with all sorts of different cart sizes. Moreover, the “slab” has a well-defined shape, typically an exponential or similar. (When I was at Wingify/VWO, we validated this theory against the data from many different customers.)
Incorporating this knowledge of how the world works provide significant improvements in statistical power. It also directly provides details on the inner workings of what’s happening, e.g. “did the lift come from more people checking out, or the same number of people buying more?”
(I should note that while spike and slab methods are typically considered Bayesian you can build a Frequentist version. My preference for Bayesian thinking is simply because it more frequently leads to ideas like this.)
In contrast, I prefer Frequentist methods when the world is adversarial?—?depending on what I do, the world will change in a bad way. As a concrete example of this, consider fraud prevention. For concreteness, suppose I’m a lender?—?the fraudster wants to borrow money (using a stolen or fake identity) and vanish without repaying.
I don’t know how he’s going to behave?—?all I know is that once he figures out what I do, he’ll change his behaviour. If I start blocking all transactions >= $500 when shipping and billing address don’t match, he’ll start buying things that cost $499.
The statistical guarantees of frequentist methods give me confidence that I’m blocking the fraudster across many possible strategies?—?therefore I don’t need to focus too much on which particular one he uses. A bound on a false discovery rate, for example, helps me be confident that a certain fraction of the people I flag as fraudsters are malicious.
In contrast, Bayesian approaches get into an “I know that he knows that I know” game.
Also, I want to give a tangential note. I do not think measuring a conversion rate is a useful example to discuss when considering Bayesian vs Frequentist methodologies. The example is too simple?—?all methods converge rapidly to the same normal distribution, the Bayesian priors in this case are always proper, there’s simply not enough complexity in the example for any of the tradeoffs between methodologies to matter. In my view an A/B test measuring revenue/visitor is perhaps the simplest example where the distinction between approaches might actually matter.
All the more reason to give a Frequentist vs Bayesian conversation more focus in the future, I’d say.
Let’s move on to lighter topics – it’s time for the Lightning round!
What is your biggest peeve in this industry?
John:
Ha?—?I don’t know really; I don’t get that peeved… I guess I hate it when people say “run it till it’s stat sig” …

Chris:
Style over substance. A SAAS app with a pretty dashboard and wrong numbers will sell a lot better than an ugly tool that actually generates lift.
Georgi:
For good or bad over the years I’ve been outspoken about my biggest peeves, most of which have to do with misuse or misunderstanding of statistics.
If you couldn’t work in Experimentation, what would you do?
Chris:
I haven’t worked in experimentation for several years, though I still A/B test things. I’ve been building machine learning systems (AI if you like buzzwords) for credit underwriting and fraud prevention. I’ve also been doing some ML to trade the stock market, but I shut that off until we recover from corona-chan.
Georgi:
I think information retrieval (as in design and development of search engines) which involves stats as well. Marketing and consumer psychology are also on the table.
John: I think last time I said, extreme backcountry snowboarder… So I guess I can’t pick that again. I play a ton of tennis; I guess I’d be a professional tennis player?—?This is fantasy right; If I pick this it means I’d inherit the skills too right?
Of course! LOL
I’ll end with this?—?since we’re all at home more often these days, how are you occupying yourselves during this time?
Chris:
Working from home right now is pretty similar to working from home previously. I have been cooking more Korean food than usual since the only supermarket that doesn’t have a long line is the local Korean store.
Georgi:
Reading, starting new research, talking to interesting people. I’d say I’m working mostly as usual.
John:
Working!
I hear that!
Thanks, everyone for joining the conversation!
Learn from Experimentation leaders from around the world every week.
Related posts:

- Don’t rely on macro goals with Gursimran (Simar) Gujral - July 26, 2024
- Navigating Experimentation at Startups with Avishek Basu Mallick - July 18, 2024
- People are the biggest challenge featuring Michael St Laurent - July 13, 2024